
what the “algorithm” is, what you think it is, and why those aren't the same

Isn’t it so convenient how I can upload a video to TikTok, and then the algorithm immediately understands that you’re my target audience?
Except that’s not happening. I’m lying to you, and you’re lying to yourself.
There is no single “algorithm,” and it certainly doesn’t “understand” anything – that implies human thought. Instead, we’re simplifying and personifying a string of different processes because it’s too difficult to confront the truth: that the “algorithm” is way more complicated and invasive than you think it is.
So let’s start over and redefine exactly what the “algorithm” is doing, because we can’t truly begin to discuss its effects until we look under the hood and see what’s really happening.
Understanding “algorithms”
An algorithm is a sequence of instructions. That’s it.
These instructions take some initial data, the input, and run it through a set of rules designed to solve a specific problem. Then we get the output: some kind of result from processing the input.

Wow, maybe an algorithm is a simple and easy thing!
Too easy, however, to bring a video directly from me to you. That requires dozens of different algorithms working together.
Step one: initial content analysis
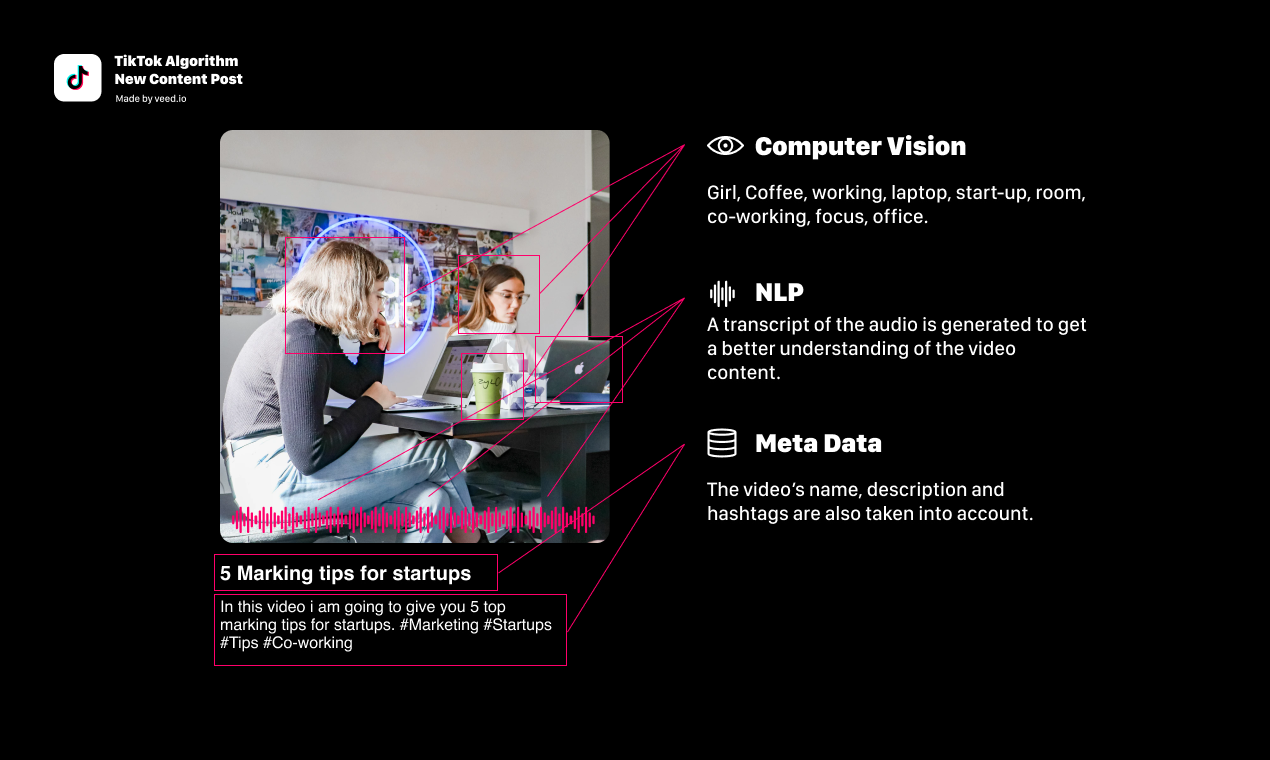
When I upload a video, at least three different algorithms begin working on it at once:
A computer vision algorithm analyzes any identifiable elements from my recording and turns those into a cluster of numbers.
A transcript of the audio is generated using NLP, and this is converted into another cluster of numbers.
The video’s metadata is tokenized and embedded into more clusters of numbers. This is so much more than hashtags. This includes the video title, description, and any captions or on-screen text.
All of these number-clusters are combined into a multidimensional representation of what my video is about. The platform is now able to compare it to similar videos and make judgments about what to do with my content.
Step two: terms of service and monetization analysis
Now that my content has been turned into a machine-readable version, a series of new algorithms evaluate it on several fronts:
Does this video conform to platform terms of service?
Does the video contain any sensitive topics that should be suppressed?
Does the video contain any duplicate content previously uploaded to the platform?
Is this video monetizable?
If my video passes all of these checkpoints, the platform starts pushing it to a small initial audience.
Step three: initial audience prediction
As soon as my video is deemed good to go, it gets sent to the first few viewers, who are usually more likely to engage with the video favorably. For established creators like myself, this “initial audience” typically consists of users who have engaged with my videos before. The type of people who comment “early!”1
Once my initial audience responds positively, a new algorithm evaluates their engagement and predicts who else might be interested in my video. Each subsequent wave of viewers is similarly re-evaluated, and the video keeps getting pushed to new people until engagement falls below a certain threshold.

But wait, how does the “algorithm” even “know” who we are?
When my video is sent from me to you, my upload is only one “input.” The other is you, and all the information you’ve given the platform. This includes the basic demographics you might expect: gender, age, location, language, operating system, network type. All of these are turned into a cluster of numbers representing you as a user. Then we add in engagement: What have you searched up? How have you engaged with previous videos?
Now it gets weird, and out of the realm of the easily explainable. Computer scientist Kevin Munger has a great piece on how your phone isn’t really “listening to you”—that’s a story we tell ourselves because the truth is even crazier. Rather, tech platforms can gather information by transferring information between phones on similar networks; by analyzing the way your thumb rests on the screen; and by tracking your activity across different applications. All of this is combined through user profile algorithms to create a machine representation of yourself. Now another algorithm matches that to the predicted audience of my video, and only then does it arrive on your “For You Page.”
Instead of one algorithm, then, the entire process might look closer to this:

The myth of the “algorithm”
Obviously, this is much too complicated to discuss colloquially, so we bundle up all these processes and collectively call them “the algorithm.” This is admittedly unavoidable. I frequently refer to “the algorithm” in my work, and I was actually still forced to simplify my explanation above.
The problem is when we accept these simplifications as reality. Now it’s easier for the platforms to sneak through additional steps or change old steps.
For example, it’s very likely that TikTok also uses a “beauty algorithm” to rank facial attractiveness and then predict audience engagement. This has real effects on how much the video is pushed to viewers, and amplifies existing social biases. We also know that platforms regularly change weightings to certain types of content—another step we really know nothing about, but one that can drastically affect how we experience the world.
The vast majority of people don’t know these processes are happening, because we’ve built up a folk representation of the “algorithm” as a reliable, impartial arbiter of taste. Whenever we anthropomorphize or simplify, we inadvertently legitimize what the tech platforms are actually doing.
Where the real meets the perception of the real
I do think there’s a general awareness that there’s more to “the algorithm” that meets the eye, even though we tend to bottle that up. The result is a kind of cognitive dissonance: we simultaneously accept the “omniscient entity” myth and feel a subconscious discomfort with it.
To me, this dissonance is where creativity happens: at the intersections of what we can perceive and what we can’t. We still feel a desire to reconcile that difference, and make new words or memes to cope.
I’ve already discussed how modern slang emerges in reaction to algorithmic oversaturation, and how the recent “Italian brainrot” trend seems to be a response to the coexistence of the real and the hyperreal. I think the same is true with a lot of our jokes and language, since they now inherently evolve through the conduits of the “algorithm,” and thus serve as contextual nods to its existence.
This makes sense: if we fully embraced reality, or our perceptions of reality, there would be no need to explain it, and no need to create. In that way, friction is a good thing. It’s a productive force for human expression. But it’s also a constant reminder to be more aware.
If you liked this post, please consider ordering my book Algospeak!! American customers can now also receive a free poster (below) if you submit proof of pre-purchase through this link here. Love you all <3

There’s probably an element of A/B testing happening as well, where another algorithm is evaluating hypotheses about whether the predicted audience is the “right” audience.
“Whenever we anthropomorphize or simplify, we inadvertently legitimize what the tech platforms are actually doing.” Was hoping for a deeper breakdown of the how and why behind this. Some interesting threads in this piece nonetheless!
Great article as always. thank you for breaking it down and including diagrams! (PS, is the Impact description correct in the poster? It seems to be missing its ending.)